
By: Joe Gaber
Contributors: Kent Brown, Byron Lai and MuleSoft Services
Extract, Transform, and Load (ETL) is a common integration pattern, usually involving movement of large data files between applications and databases, especially useful in loading data into data warehouse solutions. Many of the tools and capabilities of a good ETL solution overlap with the tools and capabilities of an Enterprise Service Bus (ESB) such as file movement, scheduling, data mapping (transformation), etc.
However, ESB’s are generally designed to optimize the use case of processing many individual real-time messages that represent transactions, with the emphasis on flexibility of transformations, processing, and connectivity and routing options. ETL tools, on the other hand, generally optimize the processing of large datasets, usually as batch jobs that run daily, with the emphasis on performance and memory usage.
Mule ESB is a widely used integration platform with many built-in features that can be combined to create a very powerful ETL application. With its variety of endpoints including HTTP/HTTPS, SFTP, File, Database, and others along with its built-in transformers and robust custom component capabilities, Mule has the building blocks to erect ETL applications that can provide many, if not all, of your enterprise’s ETL needs.
Because of the overlap in capabilities, it is a common architectural dilemma whether an ESB tool should be used for ETL scenarios or if it’s better to use specialized ETL tools. The short answer is, yes, a good ESB can cover a wide range of ETL scenarios. As long as you know how to optimize your ESB for large dataset processing and understand the limits where data volume and performance requirements dictate an ETL-specialized toolset you can be successful using an ESB – like Mule ESB – for most ETL scenarios.
Mule ESB has similar capabilities as other dedicated ETL tools such as connectivity to a wide array of databases including, but not limited to: DB2, MSSql, MySQL, AS400, Oracle, PostgreSQL, any DB that is JDBC compliant and, NoSql databases such as Hadoop, Casandra, and MongoDB.
Mule ESB’s data transformation and mapping capabilities with Dataweave is very extensive and flexible providing similar capabilities that ETL-specific tools have.
The advantage of utilizing Mule is that in addition to these building blocks, it also possesses all of the other features that an enterprise class ESB has so that when you create your ETL process all of the other features for connectivity, scheduling, instrumentation, security, batch, and orchestration become a seamless part of the overall application.
This can save a company by reducing or eliminating licensing costs associated with the purchase, implementation, and maintenance of highly specialized ETL-only tools. However, to be fair, this blog is not to suggest that Mule ESB is the optimal solution in all cases. Some ETL processes are very complex and extremely time-sensitive. In these cases, it is important to have highly refined performance metrics stipulated at the outset of designing your solution. This will give you the basis upon which you can judge if Mule’s capabilities will meet these performance objectives.
ETL-specific tools are one solution to data migration. However, these tools require a connection to the resource where the data resides and in order to make and maintain these connections, a deep knowledge of each connected system’s connectivity protocol is required.
Over time, these direct connections can become very complex to document and maintain in a complex system’s environment. Abstracting the connectivity away and allowing an ESB to provide protocol mediation greatly reduces the effort required for support.
Additionally, ETL-specific tools are “closed systems” whereas Mule is an open system. For example, if an exception is detected Mule could directly create an exception ticket in JIRA natively while most ETL processes would log the error and require a separate process to create the JIRA ticket.
Finally, many ETL processes are far more complex than simply extracting some data from one system, reformatting a few fields and loading into another system. Often, other external systems need to be called in order to lookup comparison data, apply rules from a rules engine, or enrich the data with data from other systems mid-stream of the overall processing of the original data. This requires orchestration of the requests to other systems and an ESB like Mule is best suited for that; therefore, combining the connectivity and transformation capabilities of Mule along with its powerful orchestration, batching, and clustering capabilities make it a natural choice for most ETL jobs.
Primary ETL Building Blocks
DataWeave
: A graphical data mapping feature in Mule ESB and Anypoint Studio (MuleSoft’s graphical design environment) to provide powerful mapping and transformation capabilities with an easy to use interface. Here, an XML is being transformed into a JSON with a few lines of code.
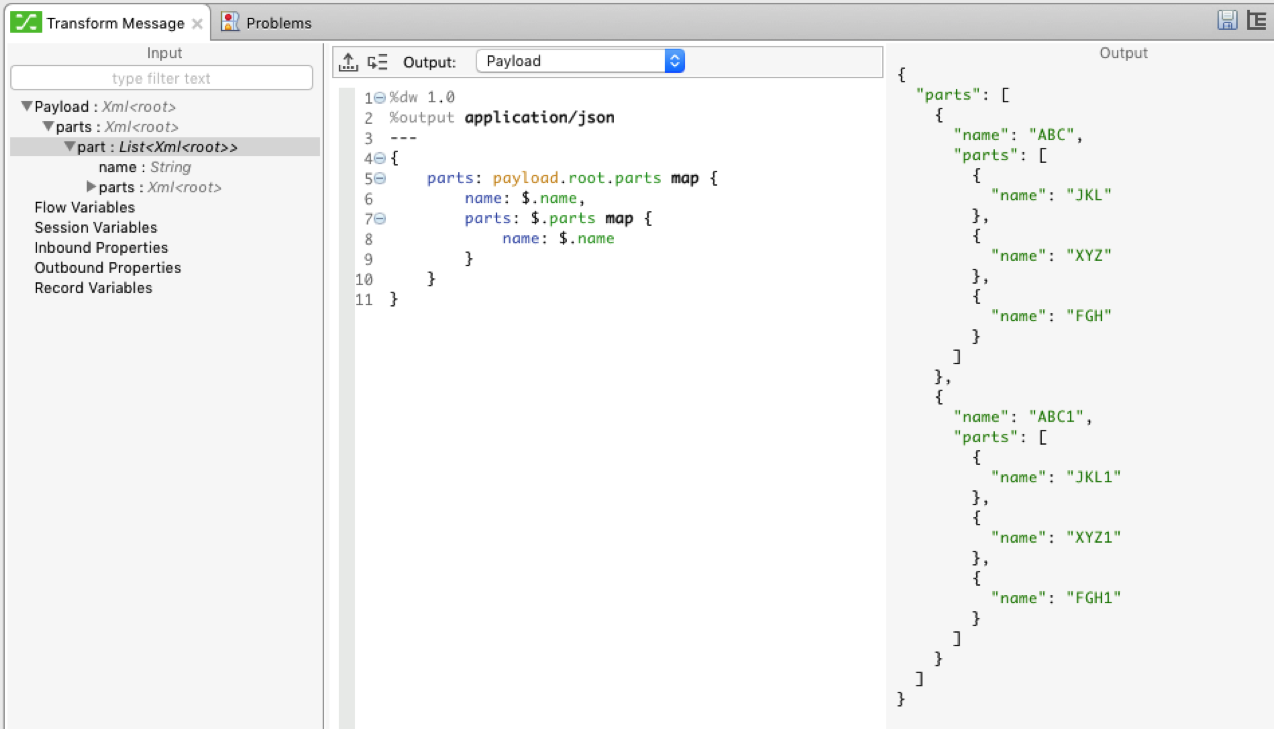
Anypoint Connectors
: Leveraging a library of Anypoint Connectors enables instant API connectivity to hundreds of popular applications and services, making it easy to extract and load data into popular sources and endpoints.
Visual data mapping
: A graphical interface eliminates the need for intricate manual coding. Simply use the graphical drag and drop interface of Anypoint Studio to accelerate development productivity.
File type support
: With support for flat and structured data formats such as XML, JSON, CSV, POJOs, Excel, and much more, organizations have flexibility over which data formats to use.
Database-level connectivity
: For cases where direct interaction to databases is required, MuleSoft’s Anypoint Connectors include options to connect to relational databases, as well as emerging Big Data platforms like MongoDB and Hadoop.
Batch Processing:
Using Mule’s Batch processor within an application, you can initiate a batch job which splits messages into individual records, performs actions upon each record, reports on the results and potentially pushes the processed output to other systems or queues. This functionality is particularly useful when working with streaming input or when engineering “near real-time” data integration between SaaS applications.
One of the many features that greatly eases the designing of a high performance ETL process is the ability to use any of the other processors within Mule, such as DataWeave, in the Input section of Batch.
The Batch processor is segmented into three primary sections: Input, Process Records, and On Complete. Within the Process Records section, you can chain as many steps as you would like, creating an orchestration within the Batch processor.
The On Complete section allows a variety of post processing tasks to take place, such as reporting.
Use Case Example
One of the latest projects that ModusBox was involved in included designing a high performance ETL process that would frequently take in very large files containing extensive marketing data, which needed to be processed in a way that would segment the incoming data stream into numerous, separate Hadoop files, conduct analytical calculations, and then upload the files into Hadoop.
Performance Requirements
As an integration specialist using Mule, it is often difficult to account for all of the varying details of a large scale project upfront. In many cases, the client isn’t aware of all of the factors until you dive into a particular aspect of the system well into the project. However, one thing that should be discussed and concluded as early as possible are performance targets.
This allows the system designer to always be thinking of design strategies that will be well suited for optimization once the application design details have been fleshed out and tested.
It is also important to make sure that whatever the performance targets are, that they are weighed against other constraints such as overall cost, quality, time to market, and must-have features. Performance optimization that takes the same amount of effort to get a 20% improvement in performance is not the same cost as a 10x improvement with the same effort. In other words, there’s diminishing returns in performance optimization.
Understanding the Data
Obviously, ETL is all about the data. However, it is all too common that the source data being extracted and transformed does not have a data dictionary and/or expert that knows every aspect of the data. It is highly recommended that before the design process even begins, that along with the performance metrics, a solid understanding of the data to be transformed exists.
Premature Optimization
It has become a best practice in application development to postpone optimizing for performance until later in the development process. Spending time on premature optimization can hinder the chore of getting the application to work correctly in the first place as you are continually chasing different designs trying to improve performance rather than getting it to work functionally correct then thoroughly testing it, and next refactoring for functional correctness. Once you have the application working correctly, you now have all the pieces in place for performance tuning efforts to be most effective.
In the above mentioned use case, the postponement of performance tuning allowed us to test the application until we felt it was functionally correct and of good quality. However, once testing was well underway, we discovered the performance was not meeting the non-functional performance metrics.
Once we had a well functioning application, we began end-to-end performance testing until we discovered the bottleneck. The most time consuming aspect of the application appeared at the point where the data was being uploaded into Hadoop due to a synchronous operation of processing each data row one at a time and the resource requirements for such high volume I/O writes. With the cause identified, custom Java code was written to enhance the deficiency. This single change improved the performance ten-fold on average.
Development Approach – Make it Work
Early on in the project, it is most important to focus on making the application work. While you should be considering design principles and proper use of Mule components, performance should not be at the top of the list yet.
Test Early and Often – Make it Right
ETL processes are often part of a larger business process that Mule ESB is there to handle. By breaking the application into small parts (small flows), it is easier to wrap them in MUnit or FunctionalTestCase tests so that each piece of the overall application can be tested in isolation. This will create a better structure to more easily identify performance bottlenecks. For example, logging can be applied at higher levels for an isolated flow, or subflow, instead of the entire process.
By following a Test-Driven Development methodology, your ETL application will end up with comprehensive tests – essentially, a test-harness. Using a test-harness will allow you to build out your application with the greatest confidence that you will be getting it to work correctly as the specifications require and will allow you to do performance optimization with confidence that it hasn’t jeopardized the accuracy of the ETL process.
Refactor for Performance – Make it Fast
Logging
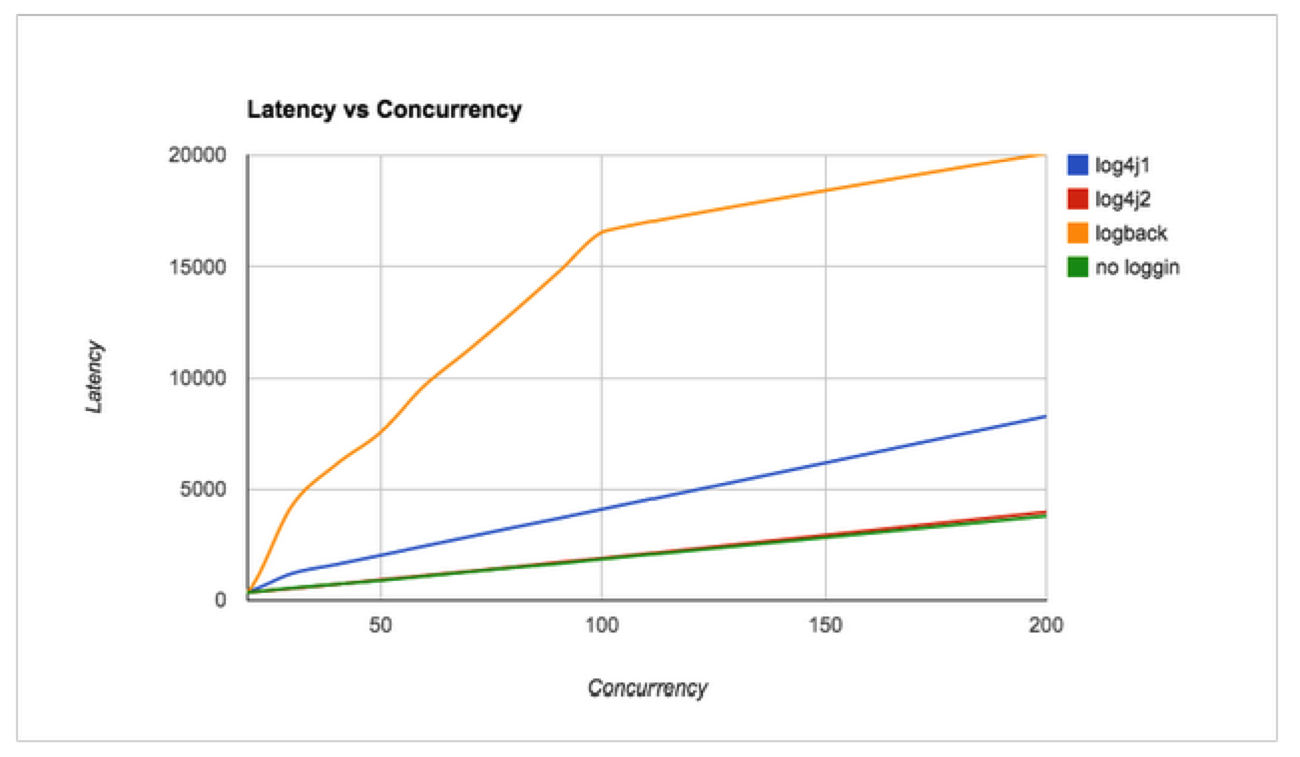
When developing your initial code, it is common to insert both permanent Log4J loggers as well as temporary System.out calls to assist in debugging and testing values. Due to this project falling under very tight timelines for delivery, when we started processing data through the system, logging levels were not optimized and the System.out calls were not removed.
Before Mule 3.6, logging operations were done synchronously. This means that a logging operation had to finish before the thread of the Mule Flow could continue.
Within a Mule container, there are a number of important functions that logging must fulfill:
- Log separation: each application/domain needs to keep its own log file
- Each application/domain needs to be able to specify its own logging config.
- If an app/domain doesn’t provide a config, a default one needs to be applied
- The performance cost of logging should be minimum
To provide a solution for the above requirements of logging, as of Mule 3.6, logging was migrated to Log4j 2.0. This allows logging operations to be asynchronous.
The lesson learned here is to pay extra attention to how you are using Log4J or other logging framework and not to let System.out calls into production code and to utilize .
 https://blogs.mulesoft.com/dev/mule-dev/mule-3-6-asynchronous-logging
https://blogs.mulesoft.com/dev/mule-dev/mule-3-6-asynchronous-logging
In addition to asynchronous logging with Log4j 2.0, unit tests and Asserts are good ways to both test and maintain your code.
I/O Operations
The original code used a synchronous operation to write data to file. As part of the tuning enhancements, the design was changed to utilize an asynchronous file multiplexer design using a write-to-bucket and a bucket-to-file process. It was the combination of asynchronous processing along with a batch style writing of the file that gave us our targeted performance.
The reason this made a big improvement to performance is that the original synchronous I/O operation of writing data had to open a connection with the hadoop File Connector for each row of data read from the incoming CSV file. Opening and closing these connections for each row is a very expensive operation. By using a ConcurrentHashMap in a custom Java component, Mule was able to hold a bucket for buffering the incoming rows until a Poll processor set for 5 seconds triggered a flush of the bucket and then write the data using the same Hadoop File Connector.
The following flow shows the call to the custom component that adds each row of the CSV file into a bucket (ConcurrentHashMap) that holds the incoming data.
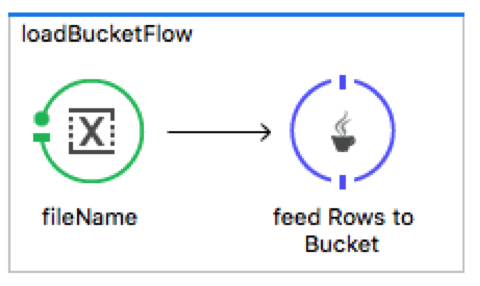
The next flow, polls every 5 seconds and then calls the drain method on the file multiplexer component. The drain method loops through each entry in the bucket and appends it to a StringBuilder. It then attaches the string to a Mule Message and forwards it to a VM connector that calls the final flow in the multiplexer process.
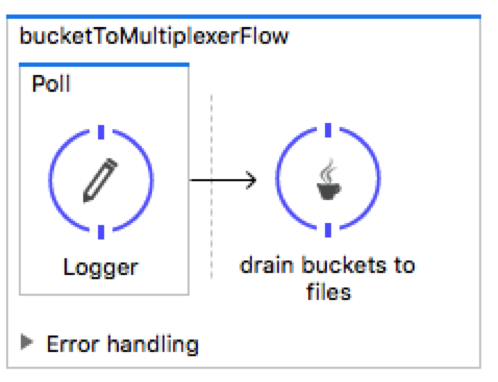
Once the message is sent to the VM queue, the following flow uses a file connector to write to disk.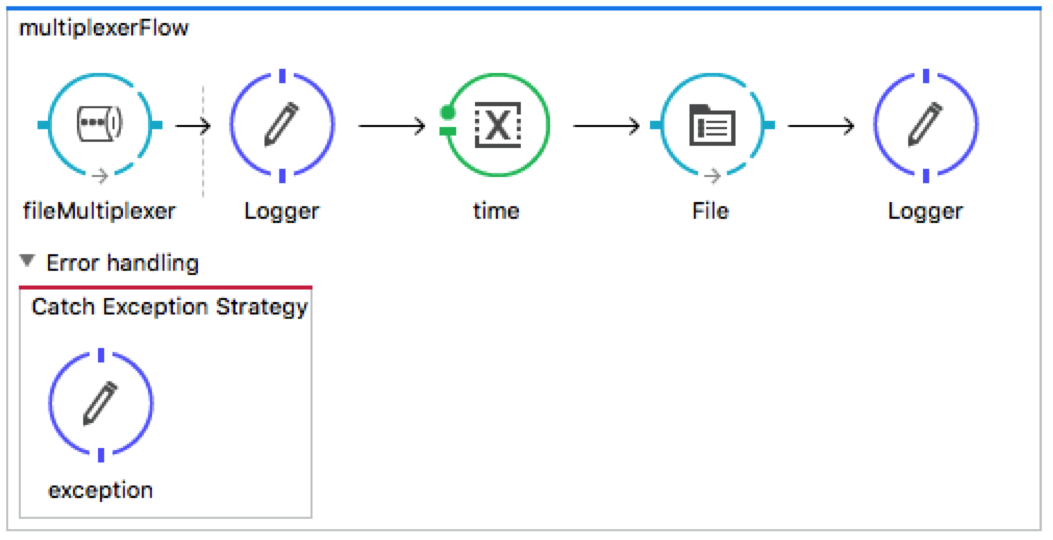
Mule Management Console
In our case, refining the logging and using the custom Java component for the buffering and flushing of data to file made enough impact that the client’s performance targets were met and we didn’t need to pursue further optimization. However, had we not reached that level of performance, the next phase of tuning would have focused on tuning Mule itself rather than the application.
Here, the Mule Management Console can provide valuable insight and tuning tools to optimize how Mule works with the JVM. Things like memory leaks or how queues are using memory heap can be readily reviewed, adjusted, and tested in order to improve overall performance.
Takeaways
Mule’s ability to modularize the ETL code, wrap it with MUnit testing, and seamlessly include it into any Mule orchestrated workflow is a very powerful solution, particularly for those who already have the desire to leverage the many other integration capabilities of Mule ESB and the Anypoint Platform.
In this case study, the most critical things that were refactored for performance included how I/O operations were being handled row by row of the file writing phase; the degree in which System.out in Groovy scripts and Java code were left in the production code; and the level of Log4J logging that was being done.
By going to a custom Java component that aggregated a group of rows to be written to file and dumping that cache every 5 seconds, managing all logging with the appropriate level of Log4J 2.0 in asynchronous mode, a 40 megabyte CSV file went from 1.0 hours to 6 minutes, a 10x performance improvement.





I am feeling motivated and now work harder to start the career in Mule-Soft, hope will get similar success. Thanks for sharing your Mule-Soft experience.